Software + Data
Measurement

OVRSeen
Virtual reality (VR) is an emerging technology that enables new applications but also introduces privacy risks. In this paper, we focus on Oculus VR (OVR), the leading platform in the VR space, and we provide the first comprehensive analysis of personal data exposed by OVR apps and the platform itself, from a combined networking and privacy policy perspective. We developed OVRSeen, a methodology and system for collecting, analyzing, and com-paring network traffic and privacy policies on OVR. On the networking side, we captured and decrypted network traffic ofVR apps, which was previously not possible on OVR, and we extracted data flows (defined as〈app, data type, destination〉). We found that the OVR ecosystem (compared to the mobile and other app ecosystems) is more centralized, and driven by tracking and analytics, rather than by third-party advertising. We show that the data types exposed by VR apps include personally identifiable information (PII), device information that can be used for fingerprinting, and VR-specific data types.

FingerprinTV
FingerprinTV is a fully automated methodology for extracting fingerprints from the network traffic of smart TV apps and assessing their performance. FingerprinTV (1) installs, repeatedly launches, and collects network traffic from smart TV apps; (2) extracts three different types of network fingerprints for each app, i.e., domain-based fingerprints (DBF), packet-pair-based fingerprints (PBF), and TLS-based fingerprints (TBF); and (3) analyzes the extracted fingerprints in terms of their prevalence, distinctiveness, and sizes. From applying FingerprinTV to the top-1000 apps of the three most popular smart TV platforms, we find that smart TV app network fingerprinting is feasible and effective: even the least prevalent type of fingerprint manifests itself in at least 68% of apps of each platform, and up to 89% of fingerprints uniquely identify a specific app when two fingerprinting techniques are used together. By analyzing apps that exhibit identical fingerprints, we find that these apps often stem from the same developer or “no code” app generation toolkit. Furthermore, we show that many apps that are present on all three platforms exhibit platform specific fingerprints.

Mon(IoT)r Testbed
The goal of the Mon(IoT)r research group is to provide awareness of the privacy implications of Internet of Things devices, and ultimately produce a means to inform users about what information they share. The Mon(IoT)r Testbed is the name of the traffic capture software that the Northeastern group has developed for the Mon(IoT)r Lab. The software is currently deployed also at Imperial College London, and a new deployment is being installed at Politecnico di Torino.

IoTLS
Consumer IoT devices are becoming increasingly popular, with most leveraging TLS to provide connection security. In this work, we study a large number of TLS-enabled consumer IoT devices to shed light on how effectively they use TLS. We gather more than two years of TLS network traffic from IoT devices, conduct active probing to test for vulnerabilities, and develop a novel blackbox technique for exploring the trusted root stores in IoT devices. We find a wide range of behaviors across devices, with some adopting best security practices but most being vulnerable in one or more ways. Specifically, we find that at least 8 IoT devices still include distrusted certificates in their root stores, 11/32 devices are vulnerable to TLS interception attacks, and that many devices fail to adopt modern protocol features over time. Our findings motivate the need for IoT manufacturers to audit, upgrade, and maintain their devices’ TLS implementations in a consistent and uniform way that safeguards all of their network traffic.
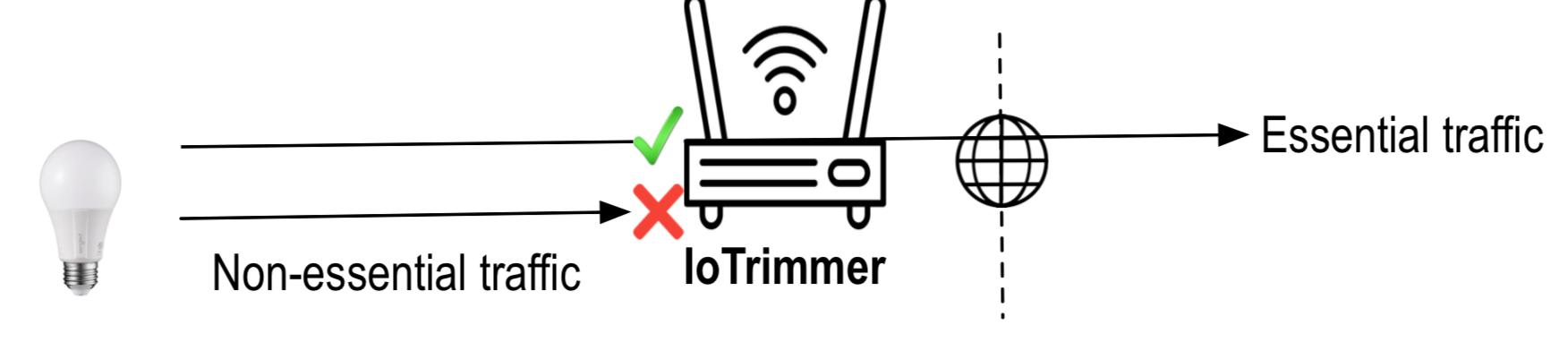
IoT Blocking
Despite the prevalence of Internet of Things (IoT) devices, there is little information about the purpose and risks of the Internet traffic these devices generate. A key open question is whether one can mitigate these risks by automatically limiting IoT devices traffic, without rendering the devices inoperable. In this work, we propose a methodology to detect and block some of this non-essential IoT traffic. We find that 16 among the 31 devices we tested have at least one blockable destination, with the maximum number of blockable destinations for a device being 11. We also discovered that all third parties observed in our experiments are blockable, and that existing blocklists are not suitable for IoT traffic. We finally propose a set of guidelines for automatically limiting non-essential IoT traffic, and we develop a prototype system that implements these guidelines.

Moby
Moby is a blackout-resistant anonymity network for mobile devices. It provides end-to-end encrypted, forward secret, and sender-receiver anonymous messaging capabilities to mobile devices. Moby utilizes a bi-modal design to do so; using Internet connectivity when available to prepare for blackouts, and ad-hoc networks during such blackouts. Moby uses a trust model based on users’ contact lists and establishes trust among users to mitigate ad-hoc flooding attacks.
We present an empirically informed simulation based on cellphone traces of 268,596 users over the span of a week for a large cellular provider to determine Moby’s feasibility. We also implement and evaluate the Moby client as an Android app.
Dark Patters
Dark patterns are user interface elements that can influence a person’s behavior against their intentions or best interests. Prior work identified these patterns in websites and mobile apps, but little is known about how the design of platforms might impact dark pattern manifestations and related human vulnerabilities. In this work, we conduct a comparative study of mobile application, mobile browser, and web browser versions of 105 popular services to investigate variations in dark patterns across modalities. We perform manual tests, identify dark patterns in each service, and examine how they persist or differ by modality. Our findings show that while services can employ some dark patterns equally across modalities, many dark patterns vary between platforms, and that these differences saddle people with inconsistent experiences of autonomy, privacy, and control. We conclude by discussing broader implications for policymakers and practitioners, and provide suggestions for furthering dark patterns research.
Adtech, Tracking, Data Brokers

Ad Targeting
In this work, we show that the demographic identity of the person shown in an ad influences who Facebook delivers the ad to. For example, using an image of a Black person will result in showing the ad more to Black audiences. Images of children are shown more to women. Images of teenage girls are shown more to middle-aged men. The findings emphasize the power of ad delivery optimization algorithms, the futility of popular approaches (such as removing sensitive targeting features), and raise question around legal implications for such optimization in job, housing, and credit advertising.

Job Ad Delivery
Ad platforms such as Facebook, Google and LinkedIn promise value for advertisers through their targeted advertising. However, multiple studies have shown that ad delivery on such platforms can be skewed by gender or race due to hidden algorithmic optimization by the platforms, even when not requested by the advertisers. Building on prior work measuring skew in ad delivery, we develop a new methodology for black-box auditing of algorithms for discrimination in the delivery of job advertisements. Our first contribution is to identify the distinction between skew in ad delivery due to protected categories such as gender or race, from skew due to differences in qualification among people in the targeted audience. This distinction is important in U.S. law, where ads may be targeted based on qualifications, but not on protected categories. Second, we develop an auditing methodology that distinguishes between skew explainable by differences in qualifications from other factors, such as the ad platform’s optimization for engagement or training its algorithms on biased data. Our method controls for job qualification by comparing ad delivery of two concurrent ads for similar jobs, but for a pair of companies with different de facto gender distributions of employees. We describe the careful statistical tests that establish evidence of non-qualification skew in the results. Third, we apply our proposed methodology to two prominent targeted advertising platforms for job ads: Facebook and LinkedIn. We confirm
skew by gender in ad delivery on Facebook, and show that it cannot be justified by differences in qualifications. We fail to find skew in ad delivery on LinkedIn. Finally, we suggest improvements to ad platform practices that could make external auditing of their algorithms in the public interest more feasible and accurate.

HARPO
Online behavioral advertising, and the associated tracking paraphernalia, poses a real privacy threat. Unfortunately, existing privacy-enhancing tools are not always effective against online advertising and tracking. We propose HARPO, a principled learning-based approach to subvert online behavioral advertising through obfuscation. HARPO uses reinforcement learning to adaptively interleave real page visits with fake pages to distort a tracker’s view of a user’s browsing profile. We evaluate HARPO against real-world user profiling and ad targeting models used for online behavioral advertising. The results show that HARPO improves privacy by triggering more than 40% incorrect interest segments and 6× higher bid values. HARPO outperforms existing obfuscation tools by as much as 16× for the same overhead. HARPO is also able to achieve better stealthiness to adversarial detection than existing obfuscation tools. HARPO meaningfully advances the state-of-the-art in leveraging obfuscation to subvert online behavioral advertising.

Khaleesi
Request chains are being used by advertisers and trackers for information sharing and circumventing recently introduced privacy protections in web browsers. There is little prior work on mitigating the increasing exploitation of request chains by advertisers and trackers. The state-of-the-art ad and tracker blocking approaches lack the necessary context to effectively detect advertising and tracking request chains. We propose KHALEESI, a machine learning approach that captures the essential sequential context needed to effectively detect advertising and tracking request chains. We show that KHALEESI achieves high accuracy, that holds well over time, is generally robust against evasion attempts, and outperforms existing approaches. We also show that KHALEESI is suitable for online deployment and it improves page load performance.

CV-Inspector
The adblocking arms race has escalated over the last few years. An entire new ecosystem of circumvention (CV) services has recently emerged that aims to bypass adblockers by obfuscating site content, making it difficult for adblocking filter lists to distinguish between ads and functional content. Thus, we develop CV-INSPECTOR, a machine learning approach for automatically detecting adblock circumvention using differential execution analysis. Given a list of sites, CV-INSPECTOR will automate the crawling, data collection, differential analysis, and prediction of whether each site was able to circumvent the installed adblocker.
YouTube-Drive
Recommendations algorithms of social media platforms are often criticized for placing users in “rabbit holes” of (increasingly) ideologically biased content. Despite these concerns, prior evidence on this algorithmic radicalization is inconsistent. Furthermore, prior work lacks systematic interventions that reduce the potential ideological bias in recommendation algorithms. We conduct a systematic audit of YouTube’s recommendation system using a hundred thousand sock puppets to determine the presence of ideological bias (i.e., are recommendations aligned with users’ ideology), its magnitude (i.e., are users recommended an increasing number of videos aligned with their ideology), and radicalization (i.e., are the recommendations progressively more extreme). Furthermore, we design and evaluate a bottom-up intervention to minimize ideological bias in recommendations without relying on cooperation from YouTube. We find that YouTube’s recommendations do direct users – especially right-leaning users – to ideologically biased and increasingly radical content on both homepages and in up-next recommendations. Our intervention effectively mitigates the observed bias, leading to more recommendations to ideologically neutral, diverse, and dissimilar content, yet de-biasing is especially challenging for right-leaning users. Our systematic assessment shows that while YouTube recommendations lead to ideological bias, such bias can be mitigated through our intervention.

AutoFR
We introduce AutoFR, a reinforcement learning framework to fully automate the process of filter rule creation for the web. We design an algorithm based on multi-arm bandits to generate filter rules while controlling the trade-off between blocking ads and avoiding visual breakage. We test our implementation of AutoFR on thousands of sites in terms of efficiency and effectiveness. AutoFR is efficient: it takes only a few minutes to generate filter rules for a site. AutoFR is also effective: it generates filter rules that can block 86% of the ads, as compared to 87% by EasyList while achieving comparable visual breakage.

COOKIEGRAPH
As opposed to third-party cookie blocking, outright first-party cookie blocking is not practical because it would result in major functionality breakage. We propose CookieGraph, a machine learning-based approach that can accurately and robustly detect first-party tracking cookies. CookieGraph detects first-party tracking cookies with 90.20% accuracy, outperforming the state-of-the-art CookieBlock approach by 17.75%. We show that CookieGraph is fully robust against cookie name manipulation while CookieBlock’s acuracy drops by 15.68%. While blocking all first-party cookies results in major breakage on 32% of the sites with SSO logins, and CookieBlock reduces it to 10%, we show that CookieGraph does not cause any major breakage on these sites. Our deployment of CookieGraph shows that first-party tracking cookies are used on 93.43% of the 10K websites. We also find that first-party tracking cookies are set by fingerprinting scripts. The most prevalent first-party tracking cookies are set by major advertising entities such as Google, Facebook, and TikTok.

Blocking JavaScript
Modern websites heavily rely on JavaScript (JS) to implement legitimate functionality as well as privacy-invasive advertising and tracking. Browser extensions such as NoScript block any script not loaded by a trusted list of endpoints, thus hoping to block privacy-invasive scripts while avoiding breaking legitimate website functionality. In this paper, we investigate whether blocking JS on the web is feasible without breaking legitimate functionality. To this end, we conduct a large-scale measurement study of JS blocking on 100K websites. We evaluate the effectiveness of different JS blocking strategies in tracking prevention and functionality breakage. Our evaluation relies on quantitative analysis of network requests
and resource loads as well as manual qualitative analysis of visual breakage. First, we show that while blocking all scripts is quite effective at reducing tracking, it significantly degrades functionality on approximately two-thirds of the tested websites. Second, we show that selective blocking of a subset of scripts based on a curated list achieves a better trade-off. However, there remain approximately
15% “mixed” scripts, which essentially merge tracking and legitimate functionality and thus cannot be blocked without causing website breakage. Finally, we show that fine-grained blocking of a subset of JS methods, instead of scripts, reduces major breakage by 3.8× while providing the same level of tracking prevention. Our work highlights the promise and open challenges in fine-grained JS blocking for tracking prevention without breaking the web.
Security Architectures and TEEs

VICEROY
GDPR and CCPA granted consumers various rights, including the right to access, modify, or delete any personal information collected by online services. Since the information contain private data, services must authenticate the consumer. This is trivial for consumers that were logged into their account during the collection, as they simply can authenticate themselves using their username and password.
However, some consumers may use the service while intentionally being logged out or just do not have an account. Authenticating such users while maintaining their privacy is a challenge. VICEROY is a novel privacy-preserving yet scalable framework that allows accountless consumers to prove data ownership.
We designed VICEROY with security, privacy, and scalability in mind and implemented it using a browser extension and a secure hardware token. We conducted extensive experiments to show VICEROY’s practicality and analyzed its security utilizing Tamarin Prover.
VERSA
With the growing popularity of IoT, massive numbers of specialized devices are deployed in many everyday settings. Such devices usually perform sensing and/or actuation. If left unprotected, ambient sensing (e.g., of temperature, motion, audio, or video) can leak sensitive and personal data. Usually, these IoT devices use low-end computing platforms with few (or no) security features. Given these constraints, can we protect the sensed data considering that all software on the device is compromised? Ideally, in order to achieve this, sensed data must be protected from its genesis, i.e., from the time when a physical analog quantity is converted into its digital counterpart and becomes accessible to software. We refer to this property as PfB: Privacy-from-Birth. In this work, we formalize PfB and design Verified Remote Sensing Authorization (VERSA) – a provably secure and formally verified architecture guaranteeing that only correct execution of expected and explicitly authorized software can access and manipulate sensing interfaces. This guarantee is obtained with minimal hardware support and holds even if all device software is compromised. VERSA ensures that malware can neither gain access to sensed data on the GPIO-mapped memory nor obtain any trace thereof. VERSA is formally verified and its open-sourced implementation targets resource-constrained IoT edge devices, commonly used for sensing. Experimental results show that PfB is both achievable and affordable for such devices.